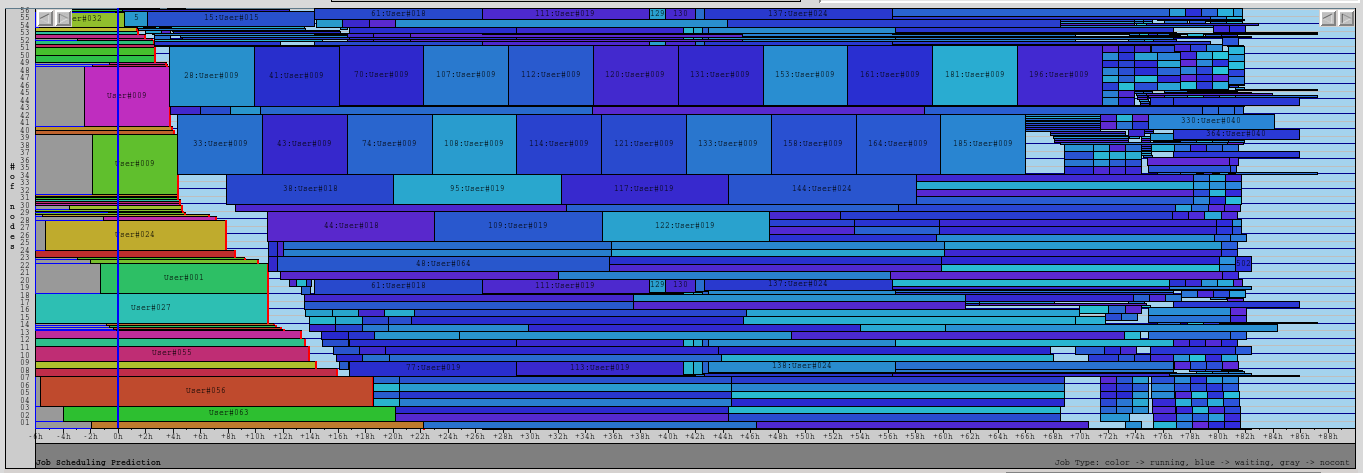
Demands on high-end HPC systems by the ESM community today encompass not only the handling of complex simulations but also machine learning as well as interactive data analysis workloads. This work package addresses the infrastructure needs of large-scale, possibly interactive, ESM data analysis workloads on future exascale supercomputers. It will enable optimizations of existing infrastructure at FZJ and DKRZ, and aims at informing decision making about future systems. The work package will be guided by use cases from the Earth Systen Science (ESS) community building on an existing application stack developed in the Pangeo project. The following aspects on heterogeneous supercomputers will be optimized: accessibility, usability, and interactivity. To enhance accessibility, options for distributed access, e.g. through Jupyter Hub, for interactive analysis of model output and fusion with observational data will be evaluated. To increase usability, the unification of working environments via the operation and the joint maintenance of containers will be explored. The container serves as a portable base software setting for data analysis application stacks and allows for long-term usability of individual working environments. Topic 4 will also help the ESS community in gaining experience with increasingly heterogeneous supercomputers, since the modular data-analysis stack already contains solutions for seamless use of various architectures such as accelerators. To advance interactive supercomputing, the inter-operation of workloads with quick turn-around times and highly variable resource demands needs to be understood and evaluated. To this end, scheduling policies will be reviewed with respect to existing technical solutions such as job preemption, utilizing the resiliency features of parallel computing toolkits like Dask, and considering scheduling requirements from Topic 2 and Topic 3. Hence, this work package provides solutions that are not limited to proof-of-concepts but with a clear roadmap for deployment on production infrastructure such as those at the FZJ and DKRZ. The use-case driven development of infrastructure solutions ensures that the results are beneficial for the broader community, covering workloads from the analysis of simulation outputs to, e.g., satellite data analysis.
Interactive large-scale analysis workflows
Use-case driven infrastructure optimization for large-scale data analysis