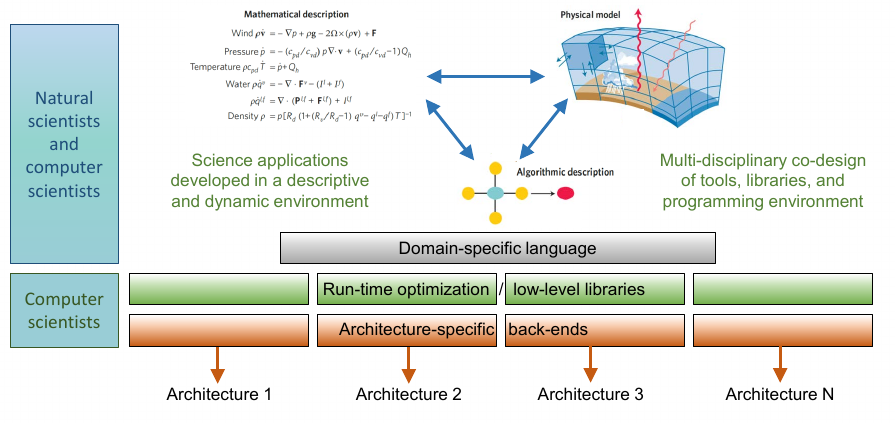
The work of the Joint Lab ExaESM is conducted in two major scientific activities. The first activity is focusing on Exascale code scalability. It tries to achieve exascale readiness by improving scalability, facilitating portability and future-proofing, increasing resource and energy efficiency to enable ESM codes to run, simulations at higher resolution, and by resolving more processes. The Joint Lab activity can support this via fostering synergies, optimising community-wide developments, therefore preparing the HGF ESM community for the first European exascale machine to be located at the Jülich Supercomputing Centre.
Performance portability and new hardware architectures
Harnessing the advantages of the rapidly evolving HPC hardware is a challenge in ESM. Although great effort has been put into partially or fully porting ESMs to accelerators, the task is far from over. As GPUs quickly evolve with sometimes relevant implication to the programming model, and as the vendor landscape enlarges, the questions on how to achieve performance across different hardware, vendors and programming models is evermore relevant. The challenge is how to achieve performance portability, while ensuring development productivity, maintainability and readability. As there are several paradigms available to address this issue, we seek synergies to answer questions such as: is it possible to strongly abstract hardware-specific code? What is the best approach to achieve performance-portable code? (e.g., see this GPU vendor/programming table: https://x-dev.pages.jsc.fz-juelich.de/2022/11/02/gpu-vendor-model-compat.html) and, can we exploit performance-portable solutions to enable, facilitate and streamline modular computing? We wish to exchange experiences, plans, success stories, pitfalls and challenges from our collective experience tackling these issues.
Development and optimization of ESM dwarfs
ESM dwarfs (or mini-apps) are concise blocks of code comprising key algorithms and mathematical kernels, abstracted from their original code base. They offer the possibility of exploring improvements and optimisations in a a focused way, avoiding the complexities of working with a full model system. They naturally encourage to work within the concept of separation of concerns, by facilitating experimenting with low-level libraries, hardware-specific programming models and optimisations, and high-level abstractions to encode them.
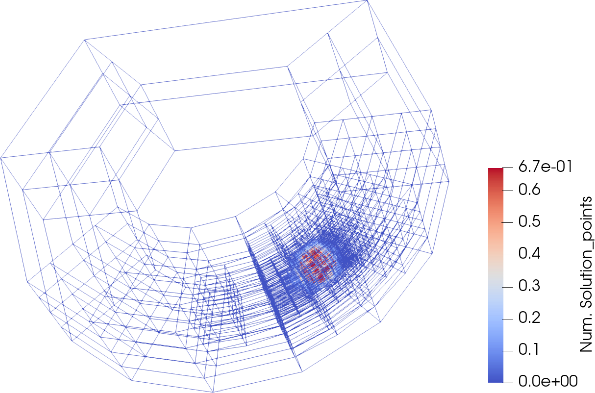
Exploitation of adaptive grids
Adaptive mesh refinement (AMR) offers many potential advantages for the scalability of ESM codes. The basic idea is to increase resolution in those regions of the problem which require it, and reduce resolution elsewhere. With AMR it is possible to reduce the number of cells without compromising accuracy. This reduces the computing effort, the memory footprint and the output data volume. There are many open challenges, e.g., dynamic load balancing, efficient memory movements upon re-meshing, and finding optimal refinement criteria. These problems are transverse, but their importance and the strategies to address them may be rather specific to the specific ESMs.
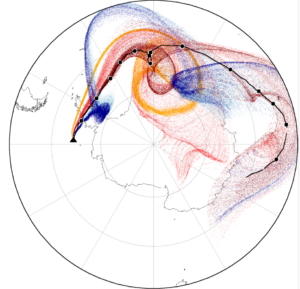
Lagrangian modeling
Lagrangian models are fundamental tools for the study of atmospheric transport processes and for practical applications such as dispersion modelling for anthropogenic and natural emission sources. However, running large-scale or long-term Lagrangian transport simulations with millions of air parcels can be numerically expensive. In this subproject, we assess the potential of using graphics processing units (GPUs) to accelerate Lagrangian transport simulations on upcoming exascale machines.
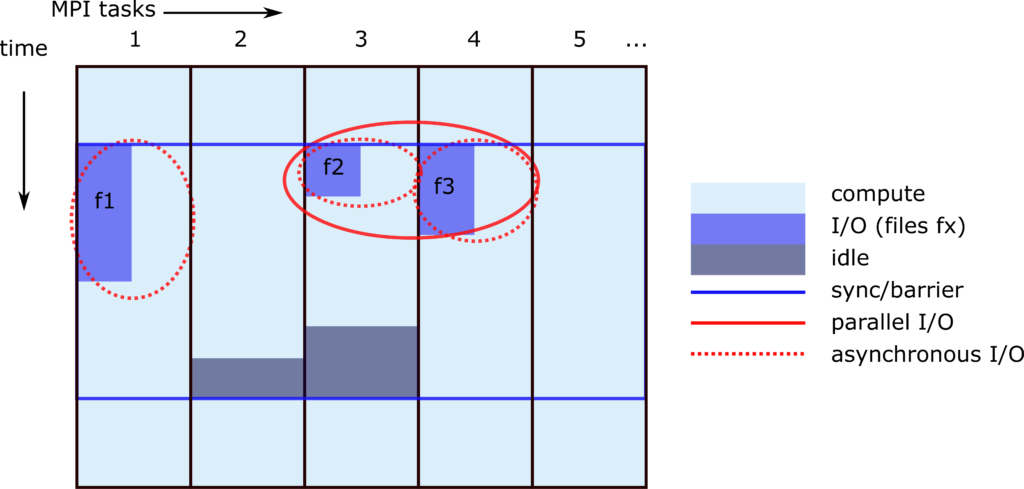
Asynchronous I/O
Exascale simulations will produce exascale data volumes, creating challenges in the storage of such volumes, but also emergent challenges in achieving high I/O throughput and dealing with the I/O bottleneck. Asynchronous I/O offers many possibilities, from strongly reducing the computational idle times during output, avoid synchronization bottlenecks between tasks, and even enabling parallel and asynchronous diagnostics and in-situ processing.